
CodeWars 일백 두 번째 문제
Updated:
Recover a secret string from random triplets
- 후…. 여러 시간을 투자하고 도저히 abcdefghijklmnopqrstuvwxyx의 테스트 코드에서 넘어가질 못해 포기했다.
- BEST CODE를 쭉 보니까 여러가지가 있겠지만 알고리즘 적으로 크게 다른 두 개를 가져왔다.
- 오늘도 이렇게 배워간다..
첫 번째 BEST CODE
public String recoverSecret(char[][] triplets) {
StringBuilder builder = new StringBuilder();
HashMap<Character, HashSet<Character>> map = buildEdgeMap(triplets);
while (!map.isEmpty()) {
char last = findLast(map);
builder.insert(0, last);
remove(map, last);
}
return builder.toString();
}
private static HashMap<Character, HashSet<Character>> buildEdgeMap(char[][] triplets) {
HashMap<Character, HashSet<Character>> map = new HashMap<>();
for (char[] cs : triplets) {
for (char c : cs) {
if (!map.containsKey(c)) {
map.put(c, new HashSet<>());
}
}
map.get(cs[0]).add(cs[1]);
map.get(cs[1]).add(cs[2]);
}
return map;
}
private static char findLast(HashMap<Character, HashSet<Character>> map) {
char getKey = 0;
for (HashMap.Entry<Character, HashSet<Character>> entry : map.entrySet()) {
if (entry.getValue().isEmpty()) {
getKey = entry.getKey();
break;
}
}
return getKey;
}
private static void remove(HashMap<Character, HashSet<Character>> map, Character c) {
map.remove(c);
for (HashSet<Character> cs : map.values()) {
cs.remove(c);
}
}
- 위의 코드는 Map와 Set을 적절히 사용한 코드이다.
- 맨 처음 문자열 배열을 Map에 Set한다.
- 문자 하나씩 꺼내서 Map에 넣는다.
- 그리고 첫 번째 문자에 두번째 문자를 두번째 문자에 세 번째 문자를 map의 value값. 즉 Set에 넣는다.
- buildEdgeMap 메소드를 완성하면 다음과 같이 된다.
- 예제는 사이트에서 나온 whatisup TEST 코드를 가지고 했다.

- 그러면 map이 비울때까지 반복을 하는데 findLast에서 문자를 가져온다.
- 문자를 가져오는 기준은 map의 value값이 없는 key 값. 즉, 문자를 가져온다.
- 그러면 위의 표에서 value값이 없는 문자는 p이다.
- p를 가져오고 map에서 삭제한다.
- 그리고 map의 모든 SET들에 대해서 p를 삭제한다.
- 그럼 다음과 같이 된다.
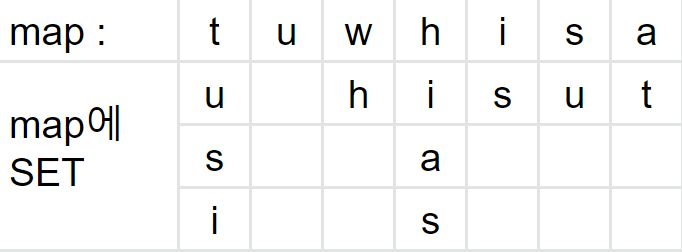
- 마지막으로 가져온 p를 문자열 앞에 둔다.
- 그리고 위의 내용을 반복한다.
- 다시 한 번 해보면 u를 가져오고 map에서 삭제하고 문자열 앞에 붙인다.
- 그럼 문자열은 up이 되고 map은 아래와 같이 된다.

- 이렇게 반복하면 whatisup이 나온다.
두 번째 BEST CODE
public String recoverSecret(char[][] triplets) {
List<Character> wordList = new LinkedList<Character>();
for (char[] triplet : triplets) {
int pIndex = -1;
for (int i = 0; i < 3; i++) {
int cIndex = wordList.indexOf(triplet[i]);
if (cIndex != -1) {
if (pIndex > cIndex) {
Character removed = wordList.remove(cIndex);
wordList.add(pIndex, removed);
cIndex = pIndex;
}
pIndex = cIndex;
} else if (pIndex != -1) {
pIndex += 1;
wordList.add(pIndex, triplet[i]);
} else {
wordList.add(0, triplet[i]);
pIndex = 0;
}
}
}
return wordList.stream().map(ch -> ch.toString()).reduce((p,n) -> p + n).get();
}
-
위의 Best 코드는 조금 따라가기 복잡하다. 두 개의 index가 자주 변경되어서 잘 따라가야 한다.
-
문자열 배열을 하나씩 가져 온다. pIndex는 항상 가져올 때마다 -1이다.
-
가져온 문자열을 하나씩 돌아가며 wordList에 어디 있는지 인덱스를 가져온다. 이게 cIndex.
-
첫 번째 if문은 해당 문자가 list에 있는 경우인데 이때 pIndex가 cIndex가 큰 경우 cIndex에 있는 문자를 삭제하고 pIndex 앞에 위치한다. 이때 pIndex는 해당 문자 앞에 문자의 위치를 말한다. 예를 들어 list에 i, t, s가 있고 tis를 처리한다고 하자. 그러면 i 차례인 경우 i의 cIndex는 0이고 t의 pIndex는 1이다. pIndex가 cIndex보다 크므로 list에서 i를 삭제한다. 그러면 list는 ts가 되고 삭제한 문자를 pIndex에 넣어준다. pIndex는 1이므로 list에 i를 넣어주면 tis가 된다. 이 부분의 이 알고리즘에 핵심이다.
-
그리고 pIndex를 cIndex로 초기화 한다. 이는 다음 검색할 문자를 위해서 현재 검색한 해당 문자의 최신 list Index 위치를 저장하기 위해서 이다.
-
두 번째 if문은 해당 문자가 list에 없으나 앞의 문자는 list에 있는 경우이다. 그러면 앞의 문자 바로 뒤에 해당 문자를 list에 넣어준다.
-
마지막 else는 앞에 문자, 해당 문자 모두 list에 없는 경우 문자열 앞에 넣어주는 경우이다. 이 경우는 문자열의 맨 앞 문자가 list에 없는 경우에 해당한다.
-
코드는 조금 복잡하지만 하나씩 따라가 보면 어렵게 느껴지진 않는다.
-
이것도 똑같이 whatisup을 TEST 코드로 시나리오를 따라가 보면
-
처음 tup 문자열을 list와 비교하며 넣는다. 그러면 일단 리스트는 t, u, p가 된다.
-
다음 whi 문자열을 list와 비교하며 넣는다. 그러면 리스트는 w, h, i, t, u, p가 된다. 아직 까진 첫 번째 if문을 실행하지 않았다.
-
다음 tsu 문자열 넣어보자. s는 list에 없고 앞에 문자 t가 list에 있기 때문에 두 번째 if문에 해당하므로 최종 list는 w, h, i, t, s, u, p가 된다.
-
다음 ats를 보자. a는 문자열 맨 앞이고 list에 없기 때문에 list는 a, w, h, i, t, s, u, p이다.
-
다음 hap를 보자. h는 있기 때문에 넘어가고 a를 보면 h보다 뒤에 있다. 그러나 list에서는 h보다 앞에 있다.
그러면 list에서 a를 삭제하고 h가 있던 index 값에 넣는다. a를 삭제 했기 때문에 삭제 전 index 값에 있는 문자는 i이므로 i 앞에 a가 들어간다. 그럼 최종 list 는 w, h, a, i, t, s, u, p가 된다.
-
다음 t i s를 보자. tis는 앞에 hap 처럼 list에 i가 t보다 앞에 있기 때문에 i를 t의 뒤로 보낸다. 그러면 w, h, a, t, i, s, u, p이 된다.
-
whs는 아무런 변화가 없기 때문에 최종 w, h, a, t, i, s, u, p이 된다.
-
두 번째 알고리즘은 코드가 조금 복잡하나 첫 번째 코드보다는 효율과 시간복잡도 측면에서는 좋은 듯 하다.