
선형시간 정렬 알고리즘(계수정렬)
Updated:
강의 사이트
- http://www.kocw.net/home/search/kemView.do?kemId=1148815
선형시간 정렬 알고리즘(계수정렬)
- 앞서서는 사전지식이 없는 Comparison 정렬 알고리즘 이었다. 이때 Comparison 정렬 알고리즘의 시간복잡도는 N log2N이고 이보다 좋을 수는 없다.
- 이제부터는 사전지식이 있는 non Comparison 정렬 알고리즘을 배울 것이다.
1. Counting Sort (계수정렬)
- N개의 정수를 정렬하라. 단 모든 정수는 0에서 K사이의 정수이다.
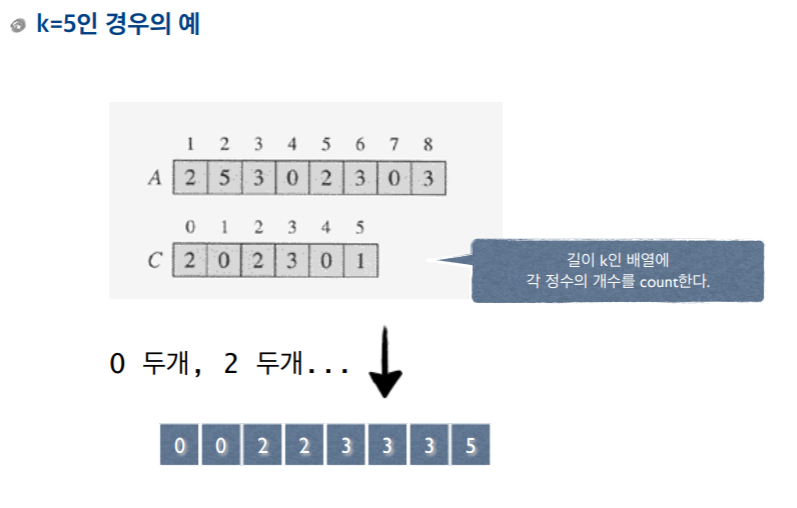
- C에다가 A를 순환하면서 해당 숫자가 C의 인덱스(위치)가 되고 해당 배열의 위치의 값을 1 증가 시킨다.

- 그러나 이런 방법은 좋지는 않은 방법이다.
- 현재는 단순하게 비교하는 값 자체로만 끝이지만 비교하는 값에 딸린 여러 값들이 있는 경우 처리하기가 힘들다.
-
예를 들어 Node(park, 010111), Node(Kim, 010222)… 이렇게 쭉 있고 이름으로 정렬한다고 했을 때 위의 방식으로 한다면 전화번호가 비교하는 값에 딸린 데이터이므로 처리하기가 힘들다.
- 그래서 아래와 같이 진행한다.
1.2 couting sort 예제
1.2.1 초기 설명
- A는 데이터가 있는 배열(즉, 정렬해야할 배열)
- C는 A의 데이터를 카운팅한 배열
- B는 C를 가지고 A를 정렬한 배열
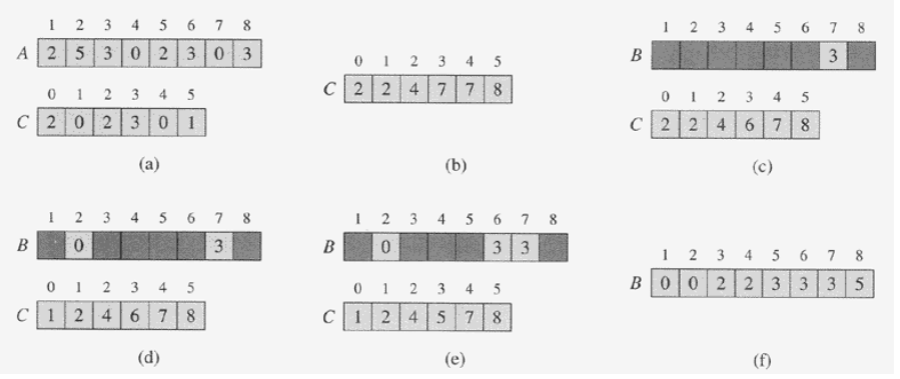
1.2.2 1단계 : (a)
- (a)의 C는 단순히 A의 데이터들을 카운팅한 배열이다.
- A에 0이 두 개, 3이 세 개 있으므로 (a)의 C를 보면 0 인덱스에 2가 있고, 3 인덱스에는 3이 있다.
1.2.3 2단계 : (b)
- (b)의 C는 (a)의 C를 누적합을 계산한 것이다.
- 예를 들어 (a)의 C를 처음부터 보자. 현재 0 인덱스에 2개(즉, 0이 두 개 있다는 뜻), 1인덱스에는 0(1은 없다)이다. 살짝 다르게 말하자면, 1보다 작고 같은 개수는 2개 이다.(0이 두개 이고 1은 없기 때문에)
- 그러므로 (b)의 C 인덱스 1을 보면 2이다.
- 이번에는 (a)의 C 인덱스 2를 보면 값이 2이다. 즉, A에 2가 2개 있다는 뜻이다.
- 그렇다면 2보다 작거나 같은 숫자가 총 4개 있다는 뜻이다. (A에 0이 2개 1은 없고, 2는 2개 이므로)
- 그래서 (b)의 C 배열 인덱스 2를 보면 4로 되어 있다.
- 이런 식으로 (b)의 C 배열 누적 값을 계산한다.
1.2.4 3단계 : (c)
- 다시 A로 돌아와서 정렬하기 위해 처음 부터 끝까지 순회한다.
- 그림에서는 A의 8번째 인덱스(A의 마지막)부터 처음까지 역으로 순회했다.
- 처음부터 마지막으로 순회해되 된다. 그림이 일단 역으로 되어 있으므로 역으로 설명하겠다.
- 처음 A의 8번째 인덱스 값은 3이다. 이때 3은 C ((b)의 C 배열이다. 쓰기 힘드니 앞으로 (b)의 C라고 생각하자.) 의 인덱스다. C의 인덱스 3을 보자. C의 인덱스 3의 값은 7이다. 다시 이때 C의 인덱스 3의 값 7은 B의 인덱스다. (B는 A를 정렬하여 넣을 배열이다. 따라서 값이 아직 없다.)
- B의 인덱스 7의 값에 처음 A 마지막 인덱스 값인 3을 넣는다.
- 왜냐하면 C가 의미하는 것은 2단계에서 말했듯이 C 배열의 각 인덱스가 가지고 있는 값들은 해당 인덱스보다 작거나 같은 수가 각 인덱스가 가르키는 값만큼 있는 것이기 때문이다.
- 다시말하면, 윗 단계에서 A의 마지막 인덱스인 8의 값이 3이다. 이때 3은 C 배열의 인덱스라고 했다. 즉, C의 인덱스는 A가 가지고 있는 데이터들의 범위 값 안에 있는 것이다. 따라서 3보다 작거나 같은 숫자 (0,1,2,3)들이 C의 인덱스 3의 값인 7만큼 있는 것이다. A를 다시 보면 0은 2 개 1은 없고, 2개 2개 3은 3개 있으므로 7개가 맞다.
- 돌와어서 B의 인덱스 7에 3을 넣는다는 의미는 A의 3보다 작거나 같은 수가 7개 있다는 의미이다.
- B의 인덱스 7에 3을 넣었으므로 C 배열 인덱스의 3의 값을 1 줄인다. 그림 (c)의 배열 C 인덱스 3을 보면 6으로 1 줄어 있다.
- 이번에는 (d)로 가보자. 여기서는 다음 A의 7번째 인덱스 값을 정렬한 그림이다. 배열 A 인덱스 7의 값은 0이다. 위에서 했듯이 이때 0은 배열 C의 인덱스 0의 값을 가르킨다. 배열 C의 인덱스 0의 값은 2이다. 이는 0보다 작거나 같은 숫자가 2개 있다는 뜻이다.
- 따라서 B의 두 번째 인덱스에 0을 넣는다. 그리고 C의 인덱스 0의 값을 1 줄인다. 그림 (d)를 보면 C의 인덱스 0의 값을 보면 1이 줄어 있다.
- 마지막으로 (e)를 보자. 이번에는 A의 6번째 인덱스 3을 정렬할 차례이다. (B에 넣을 차례라는 의미)
- A의 인덱스 6의 값은 3이다. 즉, 이때 3은 C의 인덱스 3의 값을 가르키는 것으로 C의 인덱스 3의 값은 6이다. (A의 마지막 인덱스 값을 넣었을 때 최초 그림 (b)의 C의 인덱스 3의 값인 7이 1줄어서 6이 되었기 때문)
- 다시 C의 인덱스 3의 값인 6은 B의 인덱스를 가르킨다.
- 그럼 해왔던 대로 B의 인덱스 6에 3을 넣는다.
- 그리고 마지막으로 C의 인덱스 3의 값인 6을 1 줄인다.
- 이런식으로 반복하다보면 최종적으로 그림 (f)처럼 정렬이 된다.
1.3 Psuedo Code

-
Counting Sort 예제 수도 코드
-
N은 정렬할 데이터의 크기, K는 데이터의 최대 크기 (0부터 K까지 들어온다고 가정하에)
- 1번째 for은 C를 0으로 초기화
- 2번째 for은 counting
- 3번째 for는 누적합 구하기
- 4번째 for는 누적합을 가지고 정렬하기
1.4 시간복잡도
- N >= K라고 가정한다면 O(N+K) or O(N)
- K가 클 경우 비 실용적
- Stable 정렬 알고리즘이라고 부른다. 왜냐하면 동일한 데이터에서는 먼저 입력하는 데이터 값이 먼저 출력되기 때문이다.
1.5 구현 코드
- 실제 구현 할때에는 B(아래 sort라고 보면 된다.)를 그냥 linerSort 메소드 안에서 생성하여 return 했다.
public class LinerSort {
public static void main(String[] args) {
int[] arr = new int[] {2, 5, 3, 0, 2, 3, 0, 3, 4};
int[] sort = linerSort(arr, 5);
printArray(sort);
}
private static int[] linerSort(int[] arr, int k) {
//k는 arr 데이터들의 값들이 0부터 K까지 들어온다는 것을 알고 있다는 가정이다.
int[] sort = new int[arr.length];
int[] count = new int[k+1];
// arr의 각 데이터들이 몇 개 들어 왔는지 counting 한다.
for(int i = 0; i < sort.length; i++) {
count[arr[i]]++;
}
// 카운팅한 배열 count를 누적 카운트로 바꾼다.
for(int i = 1; i < count.length; i++) {
count[i] = count[i-1] + count[i];
}
// arr을 순환하며 누적 카운트를 이용하여 sort 배열에 정렬한다.
for(int i = arr.length-1; i >= 0; i--) {
//배열은 0부터 시작하므로 count의 값에 -1을 해준다.
sort[count[arr[i]]-1] = arr[i];
count[arr[i]]--;
}
return sort;
}
private static void printArray(int[] sort) {
for(int i = 0; i < sort.length; i++) {
System.out.print(sort[i] + " ");
}
System.out.println();
}
}